在人工智能浪潮席卷全球的当下,大模型已成为驱动技术革新与产业升级的核心引擎。模型的“强大”不仅取决于算法与数据,更依赖于底层网络的坚实支撑。面对这一关键挑战,国内科技巨头腾讯(鹅厂)再次亮剑,宣布将战略重心之一聚焦于“死磕AI大模型网络技术服务”,旨在为澎湃的AI算力构建一条高速、稳定、智能的“信息高速公路”。
一、为何要“死磕”网络?大模型训练的“卡脖子”之痛
当前,百亿乃至万亿参数级别的大模型训练,已非单台或单个集群服务器所能承载。其训练过程本质上是超大规模分布式计算,需要成千上万的GPU/TPU等加速芯片协同工作。这带来了前所未有的网络挑战:
- 海量数据交互需求:在分布式训练中,各计算节点之间需要频繁同步梯度、参数和中间结果。一次训练迭代就可能产生TB级的数据通信量。网络带宽若成为瓶颈,宝贵的算力资源将大量闲置,等待数据“传输”,严重拖慢训练效率。
- 极致的低延迟要求:同步训练模式下,所有节点需等待最慢的通信完成才能进入下一轮计算。网络延迟的毫秒级抖动,都可能被放大为整个集群的等待时间,直接影响训练任务的完成时间和成本。
- 超大规模集群的稳定性:连接数千甚至数万节点的网络拓扑极其复杂。任何微小的链路故障、拥塞或性能下降,都可能导致训练任务中断或失败,造成巨大的经济损失和时间浪费。
可以说,网络性能直接决定了AI大模型研发的迭代速度、可行规模和商业成本。攻克网络技术,就是为AI的未来“疏通血脉”。
二、鹅厂出招:全栈自研网络技术体系,构筑核心优势
面对上述挑战,腾讯凭借其在云计算、即时通讯、游戏等业务中积累的深厚网络技术底蕴,系统性地推出一系列解决方案,其核心布局体现在:
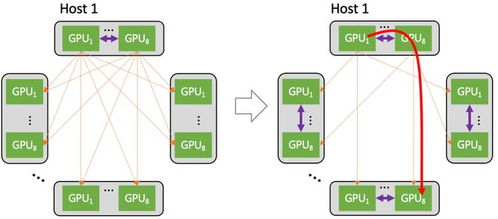
- 高性能互联基础设施:腾讯已大规模部署自研的星脉高性能计算网络。该网络采用1.6T超高速以太网、自研交换机和网卡,提供高达3.2T的集群互联带宽,并将端到端通信延迟降低至微秒级。这为大模型万卡集群提供了堪比“内总线”的高速数据传输通道,将网络对训练效率的影响降至最低。
- 智能无损网络技术:通过引入拥塞控制算法(如HPCC)、流量调度策略和可编程交换机,腾讯网络能实现近乎零丢包的数据传输。在庞大的数据洪流中,智能预测并规避拥塞,确保关键训练数据流畅通无阻,极大提升了大规模训练的稳定性和效率。
- 云网智算一体融合:腾讯将高性能网络与其遍布全球的数据中心、云计算资源深度集成。通过“算力-网络”协同调度,用户能够像使用本地资源一样,灵活、弹性地调用远端的海量异构算力(如GPU、ASIC等),组成一个逻辑统一的“超级计算机”,支撑从模型训练到推理部署的全生命周期。
- 软硬件协同优化:从自研网卡(如“沧海”)到网络协议栈、通信库(如优化后的NCCL、自研的TCCL),再到上层的分布式训练框架,腾讯进行全栈深度优化。这种垂直整合能最大化释放硬件潜力,将网络性能提升落实到最终的用户任务加速上。
三、超越技术:网络服务化,赋能千行百业
鹅厂的“出招”并不仅限于服务自身业务。其更深远的战略是将顶尖的AI大模型网络能力,通过腾讯云以服务的形式开放给全社会。这意味着:
- 对AI企业与研究者:无需巨额资本投入自建超算网络,即可按需获取世界级的高性能网络环境,大幅降低大模型研发门槛,加速创新试错。
- 对传统行业:金融、制造、医药、交通等行业在引入AI进行智能化改造时,复杂模型训练与部署中的网络难题将得到一站式解决。腾讯提供的不仅是算力,更是从网络到算法的完整生产力工具链。
- 构建生态壁垒:卓越的网络服务将吸引并留住最需要算力的高端AI客户,形成“以网络聚算力,以算力聚应用”的良性循环,巩固其在产业互联网和AI云市场的领导地位。
AI的竞赛已进入“重资产”的深水区,算力是基础,网络则是连接与放大算力价值的神经网络。腾讯此次明确“死磕AI大模型网络技术服务”,是一次从底层基础设施发力的关键落子。它不仅是为了解决自身及客户的技术痛点,更是意在定义下一代AI计算基础设施的标准,为即将到来的智能时代铺设最坚实的地基。这场围绕AI“血管”的竞赛,才刚刚进入高潮。